Example using Deepseek OCR 2
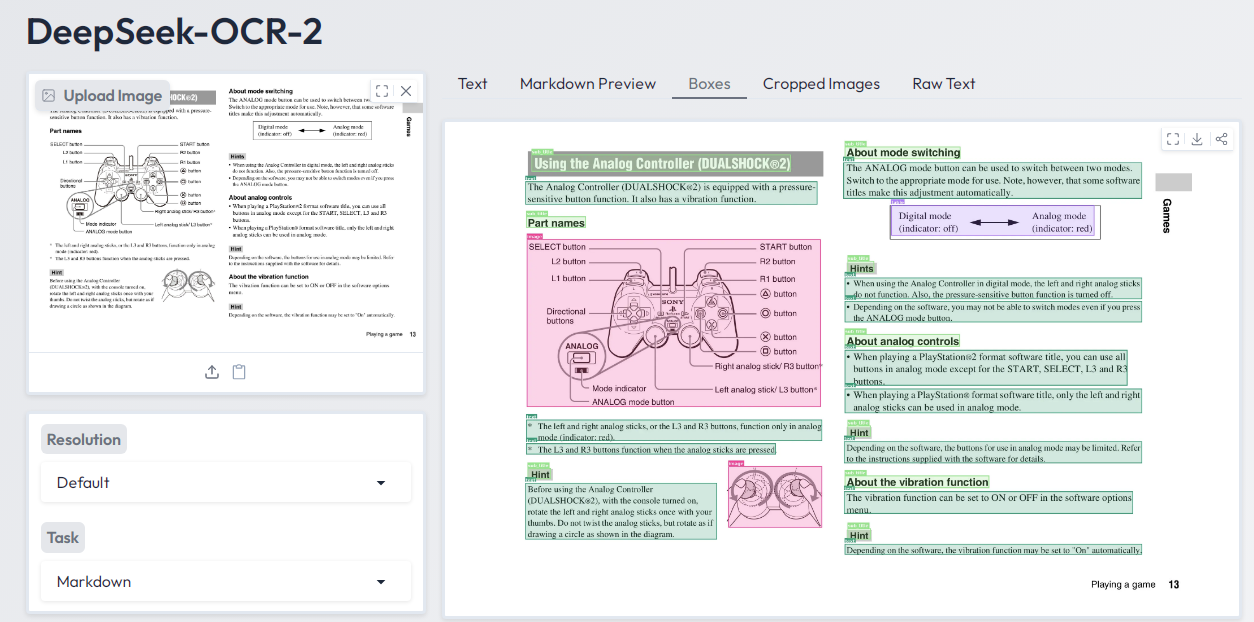
The text-image extraction and text-recognition of deepseek ocr2 are highly efficient and accurate.
You can also access OCR 2 demo on HuggingFace form here
DeepSeek OCR2 is breaking records in text extraction performance with its revolutionary visual architecture. Released by DeepSeek-AI in January 2026, this state-of-the-art 3-billion-parameter vision-language model delivers impressive results across multiple benchmarks. We’re particularly excited about its ability to maintain 97% precision even when compressing visual tokens by 10×. Furthermore, at 20× compression, the model still achieves approximately 60% accuracy, which is remarkable given such significant data reduction.
What makes DeepSeek OCR 2 stand out from previous text extraction models? First, it introduces a 3.73% accuracy improvement across benchmarks compared to earlier versions. Additionally, the system excels at handling complex document layouts, tables, and mixed text structures, often outperforming competitors like Gemini 3 Pro. On the OmniDocBench v1.5, DeepSeek OCR 2 achieves a 91.09% score, establishing itself as the leading end-to-end model. Even more impressive is its ability to process up to 200,000 pages per day on a single A100 GPU, making it incredibly efficient for large-scale document processing tasks.
In this article, we’ll explore how DeepSeek OCR 2 achieves these remarkable results through its innovative architecture, training methodology, and practical applications. Whether you’re looking to improve your document digitization workflow or simply curious about the latest advances in optical character recognition technology, this comprehensive breakdown will provide valuable insights into this groundbreaking system.
Benchmark Results and Real-World Capabilities
Rigorous testing confirms DeepSeek OCR2’s exceptional performance across multiple benchmarks, showcasing its practical capabilities for real-world document processing tasks.
OmniDocBench v1.5: 91.09% Accuracy
DeepSeek OCR 2 achieved a remarkable 91.09% overall score on OmniDocBench v1.5, representing a 3.73% improvement over its predecessor. Most impressively, the reading order edit distance decreased from 0.085 to 0.057, demonstrating the model’s enhanced ability to understand complex document layouts. Indeed, when comparing with closed-source alternatives like Gemini-3 Pro using approximately 1120 visual tokens, DeepSeek OCR2’s document parsing edit distance (0.100) outperformed Gemini’s (0.115).
Fox Benchmark: 60% Accuracy at 20x Compression
On the Fox benchmark, DeepSeek OCR2 delivers impressive results across various compression ratios:
- 97% accuracy at 10× compression using 64-100 vision tokens
- 85-87% accuracy at 15-20× compression
- 60% accuracy at maximum 20× compression
These figures demonstrate how the system balances token efficiency with text recovery precision. Although accuracy decreases at higher compression levels, the 10× compression setting provides near-lossless text recovery for most practical applications.
Multilingual OCR and Chart Parsing
Beyond standard text extraction, DeepSeek OCR2 excels at specialized tasks. The system handles documents spanning over 100 languages, alongside chart parsing capabilities that convert complex visualizations into structured HTML tables. Production data shows text repetition rates decreased from 6.25% to 4.17% on user log images and from 3.69% to 2.88% in PDF processing scenarios.
200K Pages/Day Generation on Single A100
From a throughput perspective, DeepSeek OCR2 processes approximately 200,000 pages daily on a single A100-40G GPU. For enterprise-scale operations, deploying a 20-node cluster with 160 A100 GPUs enables processing up to 33 million pages per day. Hence, the system offers both practical performance for moderate workloads and massive scalability for large digitization projects.
Context Optical Compression for Long-Text Efficiency
The core innovation of DeepSeek OCR lies in what the developers call “Contexts Optical Compression.” This approach fundamentally changes how text-heavy documents are processed by AI systems.
Token Reduction via Image Encoding
Large Language Models struggle with long documents because each word requires separate processing tokens. A traditional approach might require thousands of tokens to represent a single page of text. DeepSeek OCR2, however, flips this equation by transforming text into images first. This method eliminates conventional tokenization entirely—treating every input simply as an image.
The magic happens in the DeepEncoder component. Instead of processing words sequentially, it encodes entire document pages visually. The system compresses visual information through a 16× convolutional compressor that dramatically reduces token counts. For instance, a standard 1024×1024 pixel image that initially generates 4,096 tokens shrinks to just 256 tokens after compression. This visual representation captures not only the words themselves but also layout, typography, and spatial relationships in one compact form.
10x Compression with 97% Text Recovery Accuracy
In practical terms, the compression ratios achieved are remarkable. During testing on the Fox benchmark, DeepSeek OCR demonstrated:
- 97% accuracy at 10× compression (using 64-100 vision tokens)
- 90% accuracy at 10-12× compression
- 60% accuracy at 20× compression
This efficiency creates substantial real-world benefits. DeepSeek OCR2 outperforms leading OCR models while requiring significantly fewer tokens. Competing solutions like GOT-OCR 2.0 and MinerU 2.0 need 1,500-6,000 tokens to reach similar accuracy levels that DeepSeek achieves with just a few hundred.
Visual Memory Decay for Context Management
Perhaps most fascinating is how DeepSeek OCR2 implements a “forgetting” mechanism inspired by human memory. Rather than maintaining perfect detail for all historical context, the system can progressively downsample older content. Recent information stays crystal clear at high resolution, whereas older content becomes slightly blurrier, consuming fewer tokens while preserving essential meaning.
This approach mimics how human memory naturally fades over time. Consequently, the system can maintain ultra-long context windows without proportional increases in computational demands. In fact, through this mechanism, DeepSeek potentially opens the door to 10-million token context windows, vastly exceeding what’s possible with conventional text-only models.
DeepSeek-OCR 2 Architecture Breakdown
The architecture behind DeepSeek OCR 2’s impressive capabilities consists of multiple specialized components working harmoniously to achieve efficient text extraction.
DeepEncoder with SAM and CLIP Integration
At the core of DeepSeek OCR 2 sits the DeepEncoder, a 380 million parameter vision encoder that intelligently processes document images. This component combines two powerful neural networks: an 80 million parameter SAM-base model handling visual perception through window attention, alongside a 300 million parameter CLIP-large model responsible for knowledge extraction using dense global attention. This serial arrangement enables the system to efficiently capture both fine-grained details and global context simultaneously.
16x Convolutional Compression for Token Reduction
Between the SAM and CLIP components lies a critical innovation: the 16x convolutional compressor. This bridge reduces thousands of image patch tokens into a manageable set - transforming 4,096 tokens from a standard 1024×1024 page into just 256 vision tokens. Essentially, this compression happens before tokens enter the computationally expensive global attention layer, effectively preventing memory bottlenecks while preserving semantic meaning.
DeepSeek-3B-MoE Decoder with 6/64 Expert Routing
The compressed tokens subsequently flow into the DeepSeek-3B-MoE decoder, a Mixture-of-Experts model containing 3 billion total parameters. Notably, this decoder activates only 6 out of 64 available expert networks per token, resulting in approximately 570 million active parameters during inference. This clever design delivers the expressive power of a large model with the computational efficiency of a much smaller one.
Multi-Resolution Modes for Layout Adaptability
DeepSeek OCR 2 furthermore offers five distinct resolution modes to handle various document types:
- Tiny: 512×512 images with ~64 tokens for simple pages
- Small: 640×640 images with ~100 tokens
- Base: 1024×1024 images with ~256 tokens
- Large: 1280×1280 images with ~400 tokens
- Gundam: A dynamic tiling approach combining multiple views, ideal for ultra-high-resolution pages like newspapers or engineering diagrams
Training Pipeline and Dataset Composition
Behind DeepSeek OCR 2’s impressive performance lies a meticulously designed training pipeline and diverse dataset composition that fuels its text extraction capabilities.
Stage 1: Encoder Pretraining on Image-Text Pairs
The training process begins with independent pretraining of the DeepEncoder component. This initial stage employs a compact language model with a next-token prediction framework to teach the encoder visual comprehension fundamentals. Throughout this phase, engineers feed the system all OCR 1.0 and OCR 2.0 data, plus 100 million general images sampled from the LAION dataset. The training runs for 2 complete epochs with a substantial batch size of 1280. Technical parameters include the AdamW optimizer with cosine annealing scheduler and a learning rate of 5e-5, optimized for a training sequence length of 4096 tokens.
Stage 2: Joint Training with OCR and Vision Data
Once DeepEncoder reaches maturity, the team initiates full system training using pipeline parallelism divided into four distinct processing segments. The SAM and compressor components serve as the vision tokenizer in the first segment (PP0) with frozen parameters, while the CLIP component functions as the input embedding layer in the second segment (PP1) with unfrozen weights. For the language model, the 12 layers of DeepSeek-3B-MoE split evenly across the final two segments. The data composition features a strategic mix: 70% OCR data, 20% general vision data, and 10% text-only data. This careful balancing ensures DeepSeek OCR 2 maintains both specialized document understanding and broader visual comprehension capabilities.
30M Real Pages + Synthetic OCR 2.0 Dataset
The training dataset incorporates 30 million PDF pages spanning approximately 100 languages, with Chinese and English documents comprising 25 million pages. Moreover, specialized “OCR 2.0” data enriches training with 10 million synthetic charts (including line, bar, pie, and composite varieties), 5 million chemical formulas rendered from SMILES format, and 1 million geometric figures. This diverse dataset enables DeepSeek OCR 2 to excel at both traditional text extraction and complex visual parsing tasks involving diagrams, formulas, and structured layouts.
20-node A100 Cluster with 70B Tokens/Day Throughput
The training infrastructure operates on 20 compute nodes, each equipped with 8 NVIDIA A100-40G GPUs, allowing for data parallelism of 40 and a global batch size of 640. This configuration achieves processing speeds of approximately 70 billion tokens per day for multimodal data. In production environments, a single A100 GPU can process roughly 200,000 pages daily, while scaling to the full cluster enables throughput of approximately 33 million pages per day.
Conclusion
DeepSeek OCR 2 represents a significant leap forward in optical character recognition technology. The revolutionary visual architecture has successfully redefined what we thought possible in the text extraction field. Throughout this article, we explored how this 3-billion-parameter model achieves unprecedented accuracy while maintaining remarkable efficiency.
The benchmark results speak for themselves. DeepSeek OCR 2 achieved an impressive 91.09% score on OmniDocBench v1.5, establishing itself as the current leader among end-to-end models. Additionally, the system demonstrated exceptional compression capabilities, maintaining 97% accuracy at 10× compression and still delivering 60% accuracy even at 20× compression.
Perhaps most remarkable is the practical throughput DeepSeek OCR 2 offers. A single A100 GPU can process approximately 200,000 pages daily, while a full 20-node cluster scales this capacity to a staggering 33 million pages per day. These numbers transform the economics of large-scale document digitization projects.
The architectural innovations deserve special attention. The combination of the DeepEncoder utilizing both SAM and CLIP components, alongside the 16x convolutional compression system, creates a highly efficient text extraction pipeline. This approach fundamentally changes how AI systems handle document processing tasks.
We also examined the comprehensive training methodology that powers DeepSeek OCR 2. The two-stage process, involving encoder pretraining followed by joint training with a diverse dataset of 30 million real pages, equips the system with robust capabilities across multiple languages and document types.
The real-world applications extend beyond simple text extraction. DeepSeek OCR 2 excels at multilingual document processing across 100+ languages, chart parsing, and handling complex document layouts. These capabilities open new possibilities for businesses dealing with diverse document formats and languages.
Looking ahead, the compression techniques pioneered by DeepSeek OCR 2 point toward a future where AI systems can manage extremely long contexts without proportional increases in computational demands. The potential for 10-million token context windows suggests that document understanding AI will continue to advance rapidly in coming years.
DeepSeek OCR 2 has certainly raised the bar for what text extraction models can achieve. The combination of architectural innovation, efficient training, and impressive benchmark performance makes this system a landmark development in the field of document processing technology.
All this information is Open-Source and also avaliable at Deepseek’s official site, you can also get more deeper information from here.
Frequently Asked Questions
What is DeepSeek OCR 2 and how does it improve text extraction?
DeepSeek OCR 2 is a state-of-the-art vision-language model that significantly improves text extraction from documents. It uses innovative visual architecture to achieve high accuracy while compressing visual information, allowing it to process complex layouts and maintain 97% precision even at 10x compression.
How does DeepSeek OCR 2 handle long documents efficiently?
DeepSeek OCR 2 uses “Context Optical Compression” to efficiently process long documents. It encodes entire pages visually, compressing the information through a 16x convolutional compressor. This approach dramatically reduces token counts, allowing the system to handle lengthy documents more effectively than traditional methods.
What are the key components of DeepSeek OCR 2's architecture?
The architecture consists of a DeepEncoder (combining SAM and CLIP models), a 16x convolutional compressor, and a DeepSeek-3B-MoE decoder. This combination allows for efficient visual processing, token reduction, and adaptive handling of various document types through multiple resolution modes.
How does DeepSeek OCR 2 perform on benchmarks?
DeepSeek OCR 2 achieves impressive benchmark results, including a 91.09% accuracy score on OmniDocBench v1.5. On the Fox benchmark, it maintains 97% accuracy at 10x compression and 60% accuracy at 20x compression, outperforming many competing models while using fewer tokens.
What are the practical applications and processing capabilities of DeepSeek OCR 2?
DeepSeek OCR 2 excels in multilingual document processing (supporting over 100 languages), chart parsing, and handling complex layouts. It can process approximately 200,000 pages per day on a single A100 GPU, scaling up to 33 million pages daily with a full 20-node cluster, making it highly efficient for large-scale document digitization projects.